
تاریخچه پیشبینی فوتبال به اوایل قرن 20 برمیگردد؛ مردم در محیطهای دوستانه دور هم جمع میشدند و برنده بازی را حدس میزدند. پس از مدتی، شرکتهایی مثل Littlewoods روی کار آمدند، پیشبینی بازیها جدیتر شد و افراد دیگر از جیب مایه میگذاشتند. آن زمان همه چیز حسی بود و بیشتر روی تیم محبوب خود قمار میکردند.
اما حالا که در قرن 21 هستیم، به لطف هوش مصنوعی، پیشبینی فوتبال شکل تازهای به خود گرفته است. ابزارهای AI، نتایج مسابقات را با جزئیات باورنکردنی تحلیل میکنند. پیشبینیها دیگر حدس و گمان نیستند و همه چیز تحلیل تخصصی است. کافی است پرامپت مناسب را به یک AI بدهید تا صفر تا صد اطلاعات یک مسابقه و احتمالات بازی را به شما تحویل بدهد.
این مقاله از زرین پرداخت را به پیش بینی بازی های فوتبال با هوش مصنوعی اختصاص دادهایم. توضیح میدهیم که:
- هوش مصنوعی پیش بینی فوتبال را چگونه انجام میدهد؟
- چقدر میتوان به آن اعتماد کرد؟
- بهترین ابزارهای پیشبینی کدام هستند؟
- چگونه برنامه پیش بینی فوتبال با هوش مصنوعی بسازیم؟
- محدودیتها و خطاهای پیشبینی AI
پیشبینی فوتبال با هوش مصنوعی چیست؟
پیش بینی نتیجه فوتبال با هوش مصنوعی یعنی استفاده از مدلهای هوش مصنوعی برای تحلیل دادههای مسابقات و محاسبه احتمال نتایج مختلف. این ابزارها با بررسی آمار تیمها، عملکرد بازیکنان، مصدومیتها، نتایج گذشته و دهها عامل دیگر، احتمال برد، مساوی یا باخت هر تیم را پیشبینی میکنند.
هوش مصنوعی چطور نتیجه فوتبال را تحلیل میکند؟
پیشبینی هوش مصنوعی از نتایج فوتبال، کاملاً به آمار و ارقام وابسته است؛ هیچ اتفاق جادویی و عجیبی رخ نمیدهد و تماماً یک مسأله ریاضیاتی است.
اصلیترین چیزی که باعث میشود هوش مصنوعی عملکرد قویای در پیشبینی فوتبال داشته باشد، فناوری Machine Learning است؛ یعنی سیستمی که دادهها را دریافت کرده، میان آنها الگویابی و در نهایت پیشبینی میکند.
برای همین هم هر چقدر دادههای دریافتی هوش مصنوعی بیشتر باشد، میتواند پیشبینی دقیقتری انجام دهد.
چه اطلاعاتی روی پیشبینی تأثیر میگذارند؟
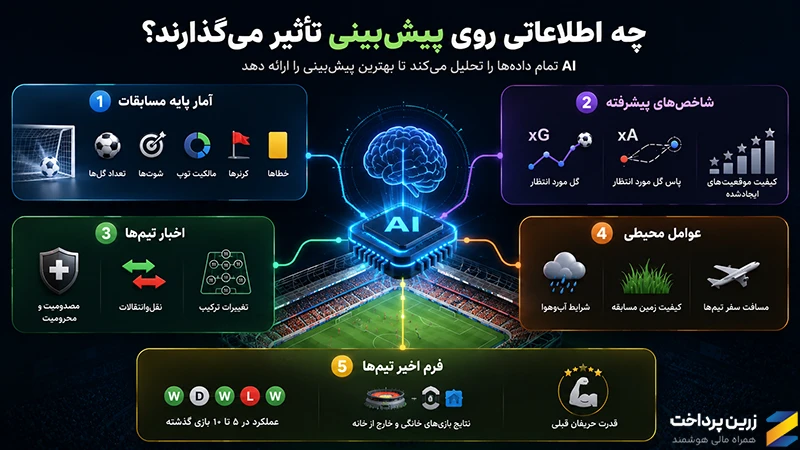 خلاصه بگوییم؛ تمام اطلاعات موجود. هوش مصنوعی مواردی را در نظر میگیرد که شاید شما اصلاً به آن فکر هم نکرده باشید. اگر بخواهیم یک دستهبندی کلی ارائه دهیم، به این شکل است:
خلاصه بگوییم؛ تمام اطلاعات موجود. هوش مصنوعی مواردی را در نظر میگیرد که شاید شما اصلاً به آن فکر هم نکرده باشید. اگر بخواهیم یک دستهبندی کلی ارائه دهیم، به این شکل است:
- آمار پایه مسابقات: تعداد گلها، شوتها، مالکیت توپ، کرنرها و خطاها
- شاخصهای پیشرفته: گل مورد انتظار (xG)، پاس گل مورد انتظار (xA) و کیفیت موقعیتهای ایجادشده
- اخبار تیمها: مصدومیت یا محرومیت بازیکنان، نقلوانتقالات و تغییرات ترکیب
- عوامل محیطی: شرایط آبوهوا، کیفیت زمین مسابقه و مسافت سفر تیمها
- فرم اخیر تیمها: عملکرد در 5 تا 10 بازی گذشته، نتایج بازیهای خانگی و خارج از خانه و قدرت حریفان قبلی
البته هوش مصنوعی قبل از تحلیل، این اطلاعات رو از صافی رد میکنه؛ یعنی دادههای غیرضروری رو حذف میکنه، استانداردسازی میکنه و اگه بازیکنی غیبت داشته باشه، مدل اثر غیبتش رو لحاظ میکنه.
با وجود حجم بالای اطلاعات، هوش مصنوعی چطور به نتیجه میرسد؟
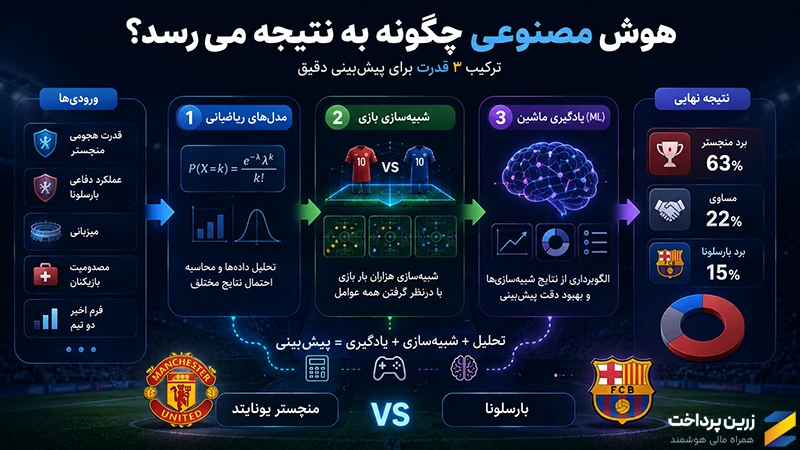
با ترکیب سه مورد: مدلهای ریاضیاتی، شبیهسازی بازی و یادگیری ماشین (ML)
بهتر است روند کار را با یک مثال توضیح دهیم:فرض کنید قرار است مسابقه منچستر و بارسلونا پیشبینی شود. هوش مصنوعی هزاران بار این بازی را بهصورت مجازی شبیهسازی میکند و عواملی مانند قدرت هجومی منچستر، عملکرد دفاعی بارسلونا، میزبانی، مصدومیت بازیکنان و فرم اخیر دو تیم را در نظر میگیرد. در پایان، احتمال هر نتیجه را محاسبه میکند.
مهمترین مدلهای آماری مورد استفاده در پیشبینی فوتبال
- توزیع پواسون (Poisson Distribution): احتمال تعداد گلهای هر تیم را بر اساس میانگین گلهای زده و خورده در بازیهای اخیر محاسبه میکند.
- سیستم رتبهبندی Elo: قدرت تیمها را بعد از هر مسابقه بهروزرسانی میکند و عواملی مانند بردهای غیرمنتظره، میزبانی و قدرت حریف را در امتیاز هر تیم لحاظ میکند.
- شبکههای عصبی (Neural Networks): این مدلها بهطور همزمان دهها متغیر مانند xG، تعداد شوتها، مصدومیت بازیکنان، شرایط آبوهوا، نتایج بازیهای رودررو و فرم اخیر تیمها را تحلیل میکنند تا پیشبینی دقیقتری ارائه دهند.
AI چقدر میتواند نتیجه مسابقه را درست پیشبینی کند؟
مدلهای مدرن هوش مصنوعی در برخی بررسیها توانستهاند برای پیشبینی برنده مسابقات فوتبال به دقتی حدود 60 تا 75 درصد برسند.
همانطور که گفتیم، دقت پیشبینی کاملاً به میزان دادههایی بستگی دارد که در اختیار هوش مصنوعی است.
هر بازی فوتبالی که انجام میشود، هزاران داده جدید تولید میکند؛ بازیکنان که بودند؟ چطور بازی کردند؟ چند بار پاس دادند؟ چند بار شوت زدند؟ بازی بیشتر در کدام قسمت زمین متمرکز بود؟ چند بار توپ گل شد؟ چند بار به تیرک خورد؟ داور چطور قضاوت کرد؟ اصلاً آبوهوا چطور بود؟ و هزاران اطلاعات دیگر.
حالا تصور کنید که فرضاً اطلاعات ده میلیون بازی فوتبال را در اختیار یک هوش مصنوعی بگذاریم؛ طبیعتآً پیشبینی که انجام میدهد بسیار دقیقتر از زمانی است که اطلاعات یک میلیون بازی را در اختیار دارد.
پیشنهاد میکنم برای اطلاعات بیشتر و مقایسه توانایی هوش مصنوعی نسبت به انسان، مقاله دقت هوش مصنوعی در پیشبینی فوتبال را مطالعه کنید.
بهترین ابزارهای هوش مصنوعی برای تحلیل فوتبال

اصولاً با هر ابزار هوش مصنوعی که امکان دریافت پرامپت داشته باشد، میتوانید مسابقات فوتبال را تحلیل و پیشبینی کنید. از ابزارهای عمومی مثل ChatGPT ،Gemini و Claude گرفته تا سرویسهایی که بهصورت تخصصی برای تحلیل و پیشبینی فوتبال طراحی شدهاند. در این بخش، روی ابزارهای تخصصی تحلیل فوتبال تمرکز میکنیم و در بخشهای بعدی، نگاهی به دیگر ابزارها خواهیم داشت.
اگر قصد خرید ابزارهای هوش مصنوعی را دارید، میتوانید از طریق زرین پرداخت اقدام کنید. اگر گزینه موردنظر شما در فهرست خدمات ما وجود نداشت، کافی است با تیم پشتیبانی ارتباط بگیرید.

1. بهترین ابزارها برای تحلیل مسابقات و پیشبینی نتایج
- Scoore.ai: اگر میخواهید قبل از شروع مسابقه یک تحلیل کامل از وضعیت دو تیم داشته باشید، Scoore.ai گزینه مناسبی است. این ابزار احتمال برد، مساوی و باخت، عملکرد بازیکنان و حتی تأثیر مصدومیتها را بررسی میکند.
- OddAlerts: اگر میخواهید علاوه بر پیشبینی، شانس هر نتیجه را دقیقتر بررسی کنید، OddAlerts انتخاب خوبی است. این ابزار با شبیهسازی هزاران حالت مختلف مسابقه، احتمال وقوع هر نتیجه را محاسبه میکند و تغییرات ضرایب را هم نمایش میدهد.
- FootballPredictAI: اگر دنبال یک ابزار ساده و سریع هستید، این گزینه مناسب است. کافی است مسابقه را انتخاب کنید تا احتمال هر نتیجه و دلیل پیشبینی را به زبان ساده ببینید.
2. بهترین ابزارها برای تحلیل ارزش آماری مسابقات
- Chad AI (Stat Sniper): اگر میخواهید آمار مسابقه را دقیقتر بررسی کنید، این ابزار روی شاخصهایی مثل گل مورد انتظار (xG)، ترکیببندی تیمها و درصد احتمال وقوع هر نتیجه تمرکز میکند و دید بهتری نسبت به عملکرد تیمها میدهد.
- SportBot AI: اگر دوست دارید هنگام تحلیل از یک دستیار هوش مصنوعی سؤال بپرسید، SportBot AI گزینه مناسبی است. این ابزار پیش بینی فوتبال با هوش مصنوعی، مسابقات را بهصورت لحظهای تحلیل میکند و میتوانید درباره هر بازی سؤال بپرسید و پاسخ دریافت کنید.
جدول مقایسه بهترین هوش مصنوعی ها برای تحلیل فوتبال
| ابزار | مناسب برای | ویژگی اصلی |
| Scoore.ai | تحلیل کامل قبل از مسابقه | نمایش احتمال برد، مساوی و باخت، بررسی عملکرد بازیکنان و تأثیر مصدومیتها |
| OddAlerts | سنجش احتمال نتایج و تحلیل آماری | شبیهسازی هزاران سناریوی مسابقه، نمایش ضرایب زنده و تحلیل احتمال هر نتیجه |
| FootballPredictAI | تحلیل سریع و ساده | نمایش درصد احتمال هر نتیجه و دلیل پیشبینی |
| Chad AI (Stat Sniper) | تحلیل آماری پیشرفته | بررسی xG، قدرت واقعی تیمها و آمارهای تخصصی مسابقه |
| SportBot AI | تحلیل تعاملی با هوش مصنوعی | تحلیل لحظهای مسابقات و امکان پرسش و پاسخ با دستیار هوش مصنوعی |
اگر فقط میخواید ببینید که هوش مصنوعی نتایج فوتبال رو چطور پیشبینی کرده، میتونید به وبسایتهایی که تحلیل AIهای مختلف رو به اشتراک میذارن سر بزنید. من یک مورد رو طبق تجربه شخصی و راحتی استفاده معرفی میکنم: سایت پیش بینی فوتبال با هوش مصنوعی
آیا تحلیل فوتبال با ChatGPT و DeepSeek هم ممکن است؟
بله کاملاً ممکن است. هم ChatGPT و هم DeepSeek میتوانند آمار، اخبار، مصدومیتها، شرایط تاکتیکی و عملکرد گذشته تیمها را تحلیل کنند. با این حال، از نظر شیوه تحلیل، کیفیت استدلال و تجربه کاربری تفاوتهایی بین آنها وجود دارد:
| معیار | ChatGPT | DeepSeek |
| تحلیل آماری | عالی | عالی |
| تحلیل تاکتیکی | عالی | بسیار خوب |
| بررسی همزمان چندین عامل | عالی | خوب |
| توضیح دلایل پیشبینی | عالی | خوب |
| ثبات در تحلیل | بالا | متوسط |
| سرعت پاسخگویی | سریع | بسیار سریع |
| مدیریت پرامپتهای پیچیده | عالی | بسیار خوب |
| تجربه کاربری | عالی | خوب |
با این حال، مهمتر از انتخاب مدل هوش مصنوعی، پرامپتی است که به آن میدهید. کیفیت پرامپتنویسی نقش بسیار مهمی در تحلیل مسابقات دارد و میتواند دقت پیشبینیها را بهطور قابلتوجهی افزایش یا کاهش دهد.
برای بررسی دقیقتر این موضوع، در یک مقاله جدا، مقایسه ChatGPT و DeepSeek را بهطور کامل انجام کردیم. یاد میگیرید چطور پرامپت حرفهای برای تحلیل مسابقات فوتبال بنویسید؛ همچنین میتونید از پرامپت آماده تحلیل فوتبال هم که بعنوان نمونه اوردیم استفاده کنید.
محدودیتها و خطاهای پیشبینی AI
با وجود تمام پیشرفتهایی که هوش مصنوعی داشته، نباید انتظار داشته باشید که همیشه نتیجه مسابقات را درست پیشبینی کند. فوتبال ورزشی غیرقابلپیشبینی است و اتفاقاتی مانند اخراج بازیکن، اشتباه داوری، مصدومیت ناگهانی یا حتی یک گل اتفاقی میتواند تمام محاسبات را تغییر دهد.
در کل هیچوقت ماهیت «ابزار» بودن هوش مصنوعی را فراموش نکنید. هوش مصنوعی فقط قرار است به شما کمک کند.
اشتباهات رایجی که ممکن است مرتکب شوید:

- احتمال را با قطعیت اشتباه نگیرید:اگر هوش مصنوعی احتمال برد یک تیم را 80 درصد اعلام کند، هنوز هم 20 درصد احتمال دارد نتیجه دیگری رقم بخورد. این درصد را بهتر است جدی بگیرید.
- آخرین اخبار تیمها را نادیده نگیرید:مصدومیت یک بازیکن، تغییر ترکیب یا تصمیم تاکتیکی سرمربی میتواند پیشبینیهای قبلی را کاملاً تغییر دهد.
- کورکورانه از هر پیشبینی پیروی نکنید:بهتر است دلیل پیشبینی را هم بررسی کنید و آن را با تحلیل شخصی و اخبار روز مقایسه کنید.
- چندین مسابقه را بیدلیل با هم ترکیب نکنید:هرچه تعداد بازیهایی که قصد پیشبینی آنها را دارید بیشتر شود، احتمال درست بودن همه پیشبینیها کمتر خواهد شد.
- انتظار نداشته باشید هوش مصنوعی همیشه درست باشد:حتی بهترین مدلهای AI هم نمیتوانند اتفاقات غیرمنتظره داخل زمین را پیشبینی کنند.
آیا میتوانیم مدل پیشبینی فوتبال خودمان را بسازیم؟
بله؛ برای اینکار نیاز به دانش برنامهنویسی و درک کافی از نحوه عملکرد هوش مصنوعی دارید. برای ساخت ابزار یا نرم افزار تحلیل فوتبال با هوش مصنوعی، کافی است مراحل زیر را انجام دهید:
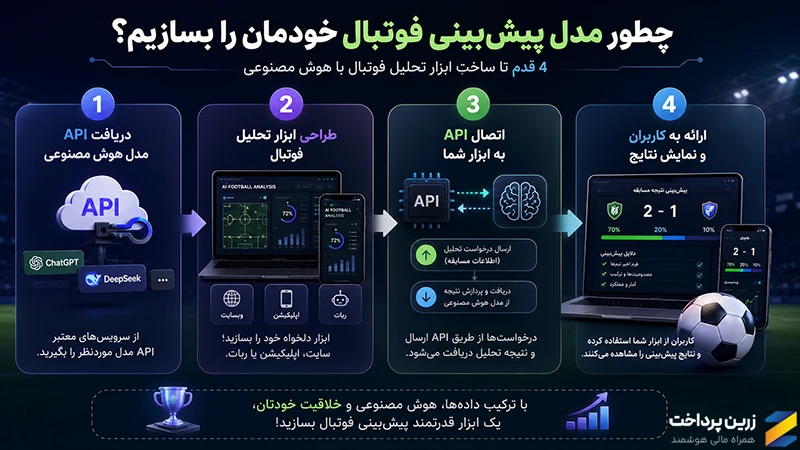
- API یکی از مدلهای هوش مصنوعی را دریافت کنیدبرای مثال، از سرویسهایی مانند ChatGPT ،DeepSeek یا سایر مدلهای هوش مصنوعی API بگیرید.
- ابزار تحلیل فوتبال خود را طراحی کنیداین ابزار میتواند یک سایت پیشبینی فوتبال با هوش مصنوعی، یک اپلیکیشن پیش بینی فوتبال یا حتی یک ربات باشد.
- API را به ابزار خود متصل کنیدبرای مثال، ربات پیش بینی فوتبال با هوش مصنوعی درخواست کاربران را از طریق API به مدل ارسال کرده و نتیجه تحلیل را دریافت میکند.
- امکان استفاده کاربران را فراهم کنیددر نهایت، کاربران میتوانند از طریق ابزار هوش مصنوعی برای تحلیل فوتبال شما، مسابقات را تحلیل کرده و نتیجه پیشبینی را مشاهده کنند.
اگه قصد کسب درآمد از پیشبینی بازیهای فوتبال رو دارید، بهتره که ابزار خودتون رو بسازید. اینطوری میتونید از چند هوش مصنوعی مختلف API بگیرید و دقت تحلیل رو بالا ببرید. در مقاله آموزش ساخت مدل پیشبینی فوتبال با پایتون و یادگیری ماشین این موضوع رو به طور کاملا تخصصی بررسی کردیم.
پیشبینی جام جهانی با هوش مصنوعی
راجع به اهمیت جام جهانی فوتبال نیاز به هیچ توضیح اضافهای نیست. امروز (1405/4/8) که این مقاله را مینویسیم، جام جهانی 2026 در حال برگزاری است و موج تقاضای پیش بینی فوتبال با هوش مصنوعی شدت بیشتری گرفته است. اکثر افراد، حتی آنهایی که هدفشان کسب درآمد از پیشبینی بازیها نیست، عجله دارند که زودتر نتیجه را حدس بزنند.
همین مسأله باعث شده که رقابت بزرگی میان ابزارهای هوش مصنوعی شکل بگیرد؛ کدامیک میتواند دقیقتر نتایج را پیشبینی کند؟
پیش بینی جام جهانی 2026 با هوش مصنوعی؛ کدام AI بهتر است؟
تا امروز (1405/4/8)، 72 بازی انجام شده و عملکرد AIهای برتر به شرح زیر است:
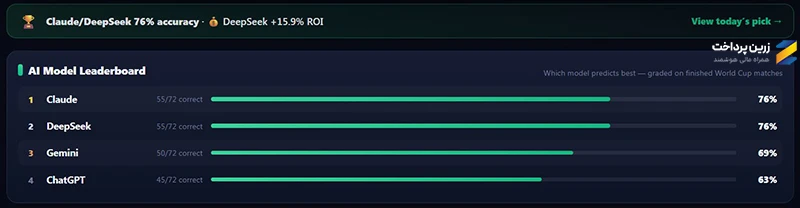 همانطور که میبینید، دیپ سیک و کلاد (Claude) موفق شدهاند با دقت 76 درصدی، نتیجه 55 بازی را درست پیشبینی کنند. بعد از آنها Gemini با 50 و ChatGPT با 45 پیشبینی صحیح، قرار گرفتهاند. منبع اطلاعات: FIFA World Cup AI predictions
همانطور که میبینید، دیپ سیک و کلاد (Claude) موفق شدهاند با دقت 76 درصدی، نتیجه 55 بازی را درست پیشبینی کنند. بعد از آنها Gemini با 50 و ChatGPT با 45 پیشبینی صحیح، قرار گرفتهاند. منبع اطلاعات: FIFA World Cup AI predictions
جمعبندی
امروزه کاربرد هوش مصنوعی در فوتبال فقط به پیشبینی نتایج مسابقات محدود نمیشود. از تحلیل تاکتیکها و عملکرد بازیکنان گرفته تا کمک به داوری، شناسایی استعدادها و حتی کاهش مصدومیتها، AI به بخش مهمی از فوتبال مدرن تبدیل شده است؛ تا جایی که فیفا هم بهصورت رسمی از هوش مصنوعی در بخشهای مختلف فوتبال استفاده میکند.
با این حال، فراموش نکنید که هیچ مدلی نمیتواند نتیجه مسابقات را با قطعیت پیشبینی کند؛ اتفاقات غیرمنتظره همیشه بخشی از فوتبال خواهند بود.
استفاده از هوش مصنوعی برای پیش بینی فوتبال صرفاً باید جنبه سرگرمی و آموزشی داشته باشد. هیچگاه سرمایه خود را به دست تحلیلهای هوش مصنوعی نسپارید.










